
Machine learning has long been a popular topic in finance that is projected to only increase in popularity in the future. A recent survey by EY and Cambridge University of over 150 financial institutions found that 78% of established non-fintech firms believe that AI will have high or very high strategic importance over the next two years. Firms that may not use these technologies today may feel compelled to in the near future in order to remain competitive.1
However, these technologies do not come without risks, which many firms categorise under the operational risk umbrella. As firms adopt this technology, they may expect senior directors and operational risk professionals to provide both risk assessment and challenge of these tools. For firms that are in the early stages of adopting these technologies or just considering their use, it is essential to train directors and non-technical managers to provide effective oversight and governance of these models.
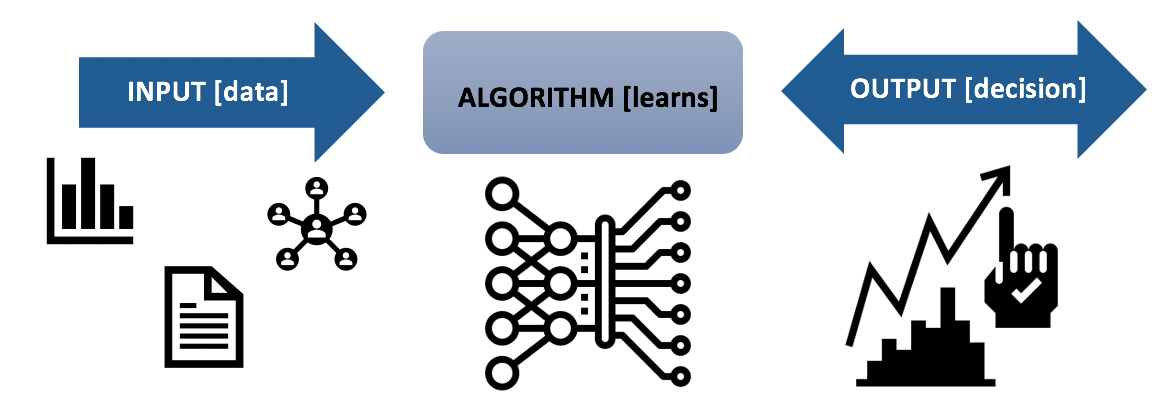
Mangers and firm leaders can’t provide oversight without a basic understanding of machine learning. Machine learning is a tool that uses data to detect patterns, find relationships, and make predictions. It is also a specific set of rules written in computer code that uses information about the world to make decisions. Machines speak in ‘computer code’, and if you want to communicate with a computer, you must speak in code. This code tells the computer exactly what to do in a given situation. When you want the computer to solve a complex problem, we may write many rules that tell it when and how to react to different circumstances. This set of rules that tell the computer how to solve a problem can be referred to as an algorithm. When people talk about machine learning, they are talking about specific algorithms or rules, that use information about the world to make decisions.2
Icon courtesy of Becris at Flaticon
These algorithms don’t make decisions in isolation, they need information or data on which to base their decisions. This information is the input – it goes into the algorithm to help it learn to make decisions. These decisions are the output of the algorithm. This process of using inputs to learn to make decisions is known as the model process.
If you use outdated data or the wrong model type or choose poor methods to measure the accuracy of the model's decisions during the model process, you will likely end up with an unsuccessful model. There are many ways a model can go wrong – and its essential that anyone charged with oversight of these tools knows what questions to ask and can thoroughly understand the answers.
The knowledge required for supervising these technologies can be organised into three categories – the machine learning models, the data used to build these models, and the methods used to manage any potential hazards. Assessing the risks and providing review of these tools requires non-technical managers and directors understand:
| The basics of machine learning tools | The data risks and requirements | How to manage the risks associated with these tools |
|
|
|
Knowledge of these three areas gives firms a strong foundation from which to begin adopting these technologies. While area experts may build the models, operational risk professionals can use their combined risk expertise and machine learning knowledge to review any potential issues throughout the model's lifetime. Understanding these tools and their potential risks further helps firms to build robust machine learning and data risk management policies.
Resources:
1. EY, Cambridge University, World Economic Forum (Jan 2020). Transforming paradigms: A global AI in financial services survey.
2. Hao, Karen (Nov 2018). What is machine learning? MIT Technology Review.
